

Benchmark zeigt: BubbleGPT Local RAG liefert verlässliche Antworten – mit Governance „by Design“
- herbertwagger
- 7. Nov. 2025
- 6 Min. Lesezeit
Wie gut ist ein RAG-System wirklich, wenn es nicht auf Demo-Daten, sondern auf echten Dokumenten aus einem regulierten Umfeld arbeiten muss? Ein großer europäischer Infrastruktur-Betreiber hat genau das getestet – mit einem umfangreichen Benchmark auf Basis seiner internen Unterlagen.

Das Ergebnis: Unsere Lösung BubbleGPT Local RAG erzielt nicht nur hohe Genauigkeitswerte, sondern zeigt auch ein Verhalten, das für Governance, Audit und Compliance entscheidend ist: präzise Antworten, mit Quellen – und ein sauberes „Ich weiß es nicht“, wenn die Dokumente keine Aussage erlauben.
1. Der Benchmark – Testaufbau in Kurzform
Für den Benchmark wurden 261 Fragen gegen eine definierte Dokumentenbasis gestellt. Die Fragen deckten ein breites Spektrum ab:
Geschäftskritische Pflichtfragen („mandatory“)
Mehrsprachige Fragen (Deutsch/Englisch gemischt)
Tabellen- und Zahlenlogik („tabular / numerical reasoning“)
Zeitliche Abhängigkeiten („temporal reasoning“)
Bild- und Diagrammfragen (inkl. OCR)
Bewusst unbeantwortbare Fragen („unanswerable“), um Halluzinationen zu testen
Die Bewertung erfolgte automatisiert über einen Semantic Similarity Score(Embedding-basiert) zwischen:
1.0 – Antwort deckt sich sehr gut mit der Referenz
0.8 / 0.6 / 0.4 – teilweise deckungsgleich
0.2 – aus Sicht der Pipeline „falsch“
2. Ergebnisse: Rohwerte und „fair gerechnete“ Performance
Offizielle Kennzahlen (reine Similarity-Metrik)
Über alle 261 Fragen:
63 % der Antworten mit Score 1.0
72 % der Antworten mit Score ≥ 0.8
Durchschnitt (Mean): ~0.78
Median: 1.0
Die typische Antwort von BubbleGPT Local RAG liegt also im Bestbereich; etwa ein Fünftel der Fragen wurde vom Similarity-Score als „schwach“ (0.2) eingestuft.
Warum die Rohwerte nicht die ganze Wahrheit erzählen
Bei einer tieferen Analyse zeigt sich jedoch: Ein Teil der 0.2-Scores betrifft Antworten, die aus Governance-Sicht genau richtig sind, aber vom reinen Ähnlichkeitsmaß unterbewertet werden, z. B.:
Korrekte „No Answer“-Antworten bei bewusst unbeantwortbaren Fragen
„Die bereitgestellten Dokumente enthalten hierzu keine Informationen …“
Inhaltlich richtige, aber anders formulierte Erklärungen (lange, saubere Paraphrasen statt kurzer Referenz-Antworten)
Korrekte Bild-/Diagramm-Beschreibungen, deren Wortlaut von der Referenz abweicht
Rechnet man diese klaren Fälle – also governance-konformes Verhalten und nachweislich richtige Antworten – fair ein, bewegt sich der realistische Durchschnittswert im Bereich von etwa 0.80–0.81.
Mit anderen Worten:
BubbleGPT Local RAG liefert in rund drei Viertel aller Fälle Antworten, die sehr nahe oder identisch zur Referenz sind – und verhält sich in kritischen Fällen lieber vorsichtig als fantasievoll.
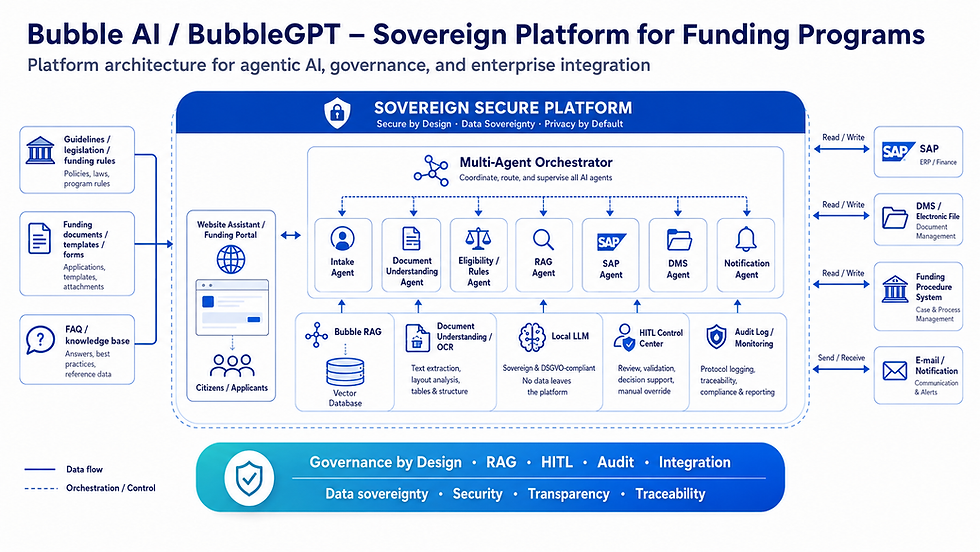
3. Warum schneidet BubbleGPT Local RAG so gut ab?
Die Benchmark-Ergebnisse sind kein Zufall. Sie spiegeln Design-Entscheidungen wider, die wir in der Architektur von BubbleGPT Local RAG bewusst getroffen haben.
3.1 Struktur-aware Chunking statt „PDF in Stücke hacken“
Viele RAG-Systeme zerschneiden PDFs blind in gleich große Textblöcke. BubbleGPT Local RAG geht hier deutlich weiter:
Structure-aware Chunking über alle relevanten Elementtypen von Unstructured.io:
Titel, Absätze, Listen
Tabellen und Formeln
Bildbeschreibungen, Captions, Diagramme
Tabellen werden nicht zerstückelt, sondern so gechunkt, dass Zeilen/Spalten-Bezüge erhalten bleiben.
Bild- und Diagramminhalte können bereits beim Ingest als Textbeschreibung ins System fließen.
Effekt im Benchmark:
Die Kategorien „Tabular reasoning“ und „tabular“ erreichen im Schnitt hohe Scores – weil BubbleGPT die Tabellenstruktur wirklich „versteht“.
Bei Image/OCR/Diagramm-Fragen lagen die Antworten inhaltlich richtig; niedrigere Scores resultierten vor allem aus sprachlichen Differenzen zur Referenz, nicht aus inhaltlichen Fehlern.
3.2 Qdrant als Vektor-Engine – schnell, präzise, filterbar
Im Kern arbeitet BubbleGPT Local RAG mit Qdrant als Vektordatenbank:
Hohe Retrieval-Qualität durch dichte Vektoren (z. B. OpenAI text-embedding-3-Modelle)
Filter und Payloads erlauben z. B. Einschränkungen nach Dokument, Datum, Typ, Sprache
Läuft on-premise oder im eigenen VPC – ideal für regulierte Umgebungen
Gerade bei geschäftskritischen Pflichtfragen zeigt sich das: Viele dieser Fragen beziehen sich auf sehr konkrete Passagen – hier ist präzises Retrieval entscheidend. Dass der Median der mandatory-Fragen bei 1.0 liegt, spricht für die Qualität dieser Pipeline.
3.3 Zwei Reasoning-Modi: Standard vs. Iterative RAG
BubbleGPT Local RAG bietet zwei Modi, die auch im Benchmark genutzt werden können:
Modus | Eigenschaften | Ideal für |
Standard RAG | Single-Pass, schnell, kosteneffizient | Faktenfragen, direkte Lookups |
Iterative RAG | Multi-Step, Frage-Dekomposition, Reasoning-Trail | „Warum/Wie/Vergleich“-Fragen, komplexe Abhängigkeiten |
Beim Iterative RAG-Modus werden komplexe Fragen in Teilfragen zerlegt, pro Schritt gezielt Kontext nachgeladen und am Ende eine konsolidierte Antwort erzeugt – inklusive vollständiger Reasoning-Historie.
Effekt im Benchmark:
Fragen mit mehreren Bedingungen oder Zwischenschritten („multiple constraints“) profitieren deutlich – insbesondere, wenn man Iterative RAG gezielt für diese Fälle nutzt.
Die Fähigkeit, Zahlen aus verschiedenen Dokumenten zu kombinieren, erklärt die guten Ergebnisse bei numerischen und tabellenbasierten Aufgaben.
3.4 Vollständige Audit-Trails: „Great answers, with receipts“
Ein Kernprinzip von BubbleGPT Local RAG ist:
Keine Antwort ohne Belege.
Für jede Frage werden:
die verwendeten Kontext-Chunks inkl. Dokument, Seite, Score gespeichert,
ein kompletter RAG-Kontext als JSON abgelegt,
und – bei Iterative RAG – die Reasoning-Schritte pro Iteration dokumentiert.
Für Batch-Auswertungen (wie im Benchmark) bedeutet das:
Jede Zeile in der Excel-Auswertung lässt sich zurückverfolgen:
Welche Dokumente wurden herangezogen?
Welche Tabellen oder Bilder waren beteiligt?
Welche Zwischenschritte hat die KI gemacht?
Governance, Audit & Troubleshooting werden dadurch erheblich vereinfacht.
3.5 On-Prem, souverän, integrierbar
BubbleGPT Local RAG ist bewusst als lokale oder Private-Cloud-Lösung konzipiert:
Dokumente, Vektoren und Logs verbleiben in der eigenen Infrastruktur.
Cloud-LLMs (z. B. GPT-4o) werden nur verwendet, wenn das explizit gewünscht ist.
Über eine einfache API kann BubbleGPT nahtlos in bestehende Systeme integriert werden:
z. B. als RAG-Backend für BubbleChat / LibreChat
oder als eigenständiger Dienst für Batch-Auswertungen (Excel in / Excel + JSON out).
Gerade für den Benchmark – der in einem regulierten Umfeld stattfand – war das ein entscheidender Faktor: hohe Genauigkeit, ohne Daten nach außen zu geben.
4. Governance: Wenn „keine Antwort“ die richtige Antwort ist
Ein besonders wichtiges Ergebnis des Benchmarks betrifft die „unanswerable“-Fragen:
Der Test enthielt bewusst Fragen, die sich nicht aus den bereitgestellten Dokumenten beantworten lassen sollten.
BubbleGPT Local RAG hat in mehreren Fällen genau das getan, was ein Enterprise-System tun soll:
klar kommuniziert, dass die Information nicht im Kontext vorhanden ist,
und keine Fantasie-Antwort erfunden.
Die verwendete Similarity-Metrik bewertet diese Antworten jedoch mit 0.2 – also genauso schlecht wie eine echte Halluzination.
Aus Sicht eines KI-Betriebs in regulierten Branchen (Banken, Versicherungen, öffentliche Hand) gilt jedoch das Gegenteil:
„Safe failure“ – also ein sauberes „kann ich aus den Dokumenten nicht beantworten“ – ist ein Feature, kein Bug.
Dass BubbleGPT Local RAG dieses Verhalten zeigt, ist einer der Gründe, warum wir den Benchmark nicht nur als Genauigkeitstest, sondern auch als Governance-Validierung verstehen.
5. Was bedeutet das für Unternehmen?
Zusammengefasst zeigt der Benchmark:
Hohe fachliche Trefferquote
Offizieller Durchschnitt: ~0.78
Fair bewertet (inkl. korrekter No-Answer- und Bild-Fälle): ~0.80–0.81
63 % der Antworten im Bestbereich (1.0), 72 % bei ≥0.8
Überzeugende Performance in schwierigen Kategorien
Tabellen, numerische Logik, Bilder/OCR, komplexe Fragen mit mehreren Bedingungen
Vorbildliches Governance-Verhalten
Korrektes „No Answer“, wo Dokumente keine Grundlage bieten
Lücken werden klar kommuniziert, statt „weggeschrieben“
Produktionsreife Architektur
On-prem, Qdrant, struktur-bewusste Chunking-Pipeline
Vollständige Logs, Audit-Trails, JSON-Kontexte pro Frage
Interaktive Q&A und Batch-Verarbeitung mit Excel
Für Unternehmen heißt das konkret:
Wissensarbeit beschleunigen, ohne die Kontrolle über Daten und Antworten zu verlieren.
RAG-Pilotprojekte nicht nur als Tech-Demo, sondern direkt mit Audit- und Compliance-Fähigkeiten starten.
Bestehende Chat-Frontends (z. B. BubbleChat, LibreChat, Intranet-Portale) können BubbleGPT Local RAG einfach als souveränes RAG-Backend nutzen.
6. Fazit: Warum dieser Benchmark mehr ist als nur eine Punktzahl
Der durchgeführte Benchmark bestätigt, dass BubbleGPT Local RAG zwei Dinge gleichzeitig schafft:
Hohe Genauigkeit bei fachlichen Fragen – messbar und reproduzierbar.
Verantwortungsvolles Verhalten in Graubereichen – kein blinder Optimismus, sondern nachvollziehbare, dokumentierte Entscheidungen.
Oder anders formuliert:
BubbleGPT Local RAG liefert starke Antworten – und immer die Belege dazu.

Wenn Sie wissen möchten, wie wir diesen Benchmark aufgebaut haben, wie BubbleGPT Local RAG in Ihre Umgebung integriert werden kann oder welche Ergebnisse in Ihrem konkreten Use Case zu erwarten sind, sprechen Sie uns gerne an.
Unternehmensprofil – INTRANET Software & Consulting GmbH
Die INTRANET GmbH mit Sitz in Kärnten ist ein österreichischer Spezialist für KI-gestützte Unternehmenslösungen und Plattformentwicklung. Mit über 20 Jahren Erfahrung in der Digitalisierung begleitet das Unternehmen Banken, KMU, öffentliche Einrichtungen und Konzerne bei der Implementierung zukunftsorientierter Systeme.
Die Schwesterfirma Bubble Explorer Inc. (Silicon Valley) unterstützt mit internationalem Know-how im Bereich generativer KI und Plattform-Skalierung.

BubbleGPT – Ihre unternehmensinterne KI-Plattform
BubbleGPT ist eine modulare KI-Lösung für Unternehmen, die auf Retrieval-Augmented Generation (RAG), Multi-Agenten-Systemen und einem 100 % Open-Source-Tech-Stack basiert.
Ihre Vorteile
Souverän & sicher: Betrieb on-prem oder in europäischer Cloud, DSGVO-konform
Open-Source: Kein Vendor-Lock-in, langfristige Unabhängigkeit
Schnittstellenfreudig: Anbindung an ERP, CRM, SharePoint, Jira, MS365, etc.
Flexibel & modular: Von PoC über Assistenzsysteme bis zur kompletten Prozessautomatisierung
Praxisbeweise



Kontakt
Herbert Wagger CEO – INTRANET Software & Consulting GmbH📍 Krumpendorf am Wörthersee📞 +43 664 184 42 34✉️ wagger@intranet-consulting.at🌐 www.bubbleexplorer.com
Markus Orlitsch CEO – Bubbleexplorer, Inc. 📍 San Francisco 📞+43 677 62798353 | markus@bubbleexplorer.com


Kommentare